はじめまして、ソリューションアーキテクト部の金杉です!
最近、私が関わっている業務の一環として、IDCFクラウドでLVS(Linux Virtual Server)を立ててみました。エンジニアブログでまだ紹介されてなかったということで、今回はIDCFクラウドのCentOSで、keepalivedでLVSを使ったロードバランサーの構築を紹介します。
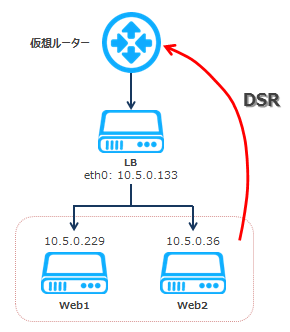
▲今回構築する構成
ご存知の方もいらっしゃると思いますが、IDCFクラウドではアカウントごとに仮想ルーターがついています。仮想ルーターの詳細についてはこちらをご覧ください。
仮想ルーターについているロードバランサー機能はとても便利なのですが、LVSを使う必要がある構成も稀ではないですよね。LVSを使いたい主な理由をまとめると:
- 処理が速いので大量にバランシングできる
- アプリサーバー側で接続元IPアドレスを特定できる
- keepalivedを使うことによって、サービスに近いヘルスチェックができる
- 内部トラフィックとサービス側のバランシングを分けることができる
などなどあります。そしてLVSはみんなが大好きなOSS(オープンソースソフトウェア)なので、導入も手軽にできるのです!
一方keepalivedは、LVSと組み合わせて使うデーモンです。LVSの設定は、keepalived.confファイルを編集するだけで反映されるので、とても便利です。keepalivedが提供する機能は主に2つあります:
- バランシングしているサーバーのヘルスチェック
- VRRPを用いたロードバランサーの冗長化
今回は、keepalivedの機能1、サーバーのバランシング+ヘルスチェックの部分についてです。
ではここから構築に入ってみましょうー!
仮想マシンの準備
CentOS 6.6の仮想マシンで構築をします。バランシングするリアルサーバー(Web)2台とバーチャルサーバー(LVS)1台、計3台の仮想マシンを以下のスペックで作成します。「台数」選択の部分で、【3】を選択すると一気に作れてしまいます★
マシンタイプ Light.S1 イメージ CentOS 6.6 64-bit ボリューム そのまま SSH Key 作成 仮想マシン台数 3 ネットワークインターフェース そのまま 詳細情報・仮想マシン名 Web1, Web2, LB 詳細情報・プライベートIPアドレス 自動設定

仮想マシンは、それぞれSSHできるように「IPアドレス」の設定をしておいてください。 そしてLVSサーバーLBに関しては、HTTP通信ができるように80番ポートもあけておいて下さい。
詳しくは、めちゃ楽ガイドをご参照ください!
今回の構成
今回は、このような構成になります。
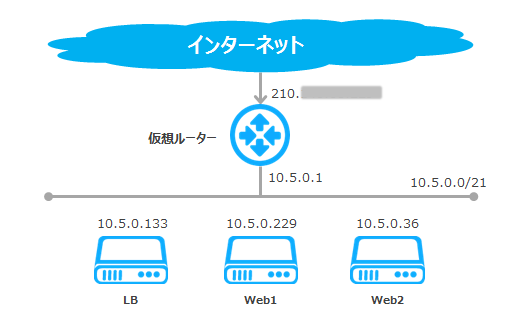
公開用のIPは仮想ルーターのソースIPで、裏にLB、Web1、Web2などが同じセグメントに設置されています。LBがバランシングする時の通信を詳しく見てみると、こうなります。
ここで2点補足です。
- 先ほども出てきたロードバランサー用語として、ロードバランサーのバランシング対象を集約する上位側のことを「バーチャルサーバー」と呼び、下位側のWeb等のことを「リアルサーバー」と呼びます。クライアントから見ると、トラフィックの宛先は実際のサーバーではなく、それらを1つのサーバーのように見せかけて、集約しているロードバランサーです。なのでこのロードバランサーをバーチャルサーバーと呼び、実際にリクエストに返信するバランシング対象をリアルサーバーと呼びます。この図で見ると、リクエストの宛先はバーチャルサーバーのIPアドレス、10.5.0.133になります。
- 今回は、DSR(Direct Server Return)方式を使ってリクエストをクライアントに返します。この方式では、LVS宛に来たリクエストは、リアルサーバーにフォワードされた後、LVSを経由せず直接クライアントに返されます。一方、NAT(Network Address Translation)方式もありますが、これはロードバランサーを経由し、IPアドレスを書き換えてクライアントに返す方法のため、ロードバランサーに負荷がかかります。よって、LVSを使う時はDSR構成がよく使われます。
Step1. keepalivedの準備
LVSの設定をしていきます。
必要なパッケージをダウンロード
<code>[root@LB ~]# yum -y install ipvsadm keepalived</code>
自動起動の設定
<code>[root@LB ~]# chkconfig keepalived on</code> <code>[root@LB ~]# chkconfig --list keepalived</code> <code>keepalived 0:off 1:off 2:on 3:on 4:on 5:on 6:off</code>
パケット転送の設定
<code>[root@LB ~]# vim /etc/sysctl.conf</code> <code>net.ipv4.ip_forward = 1 (0から1へ変更)</code> <code>[root@LB ~]# sysctl -p</code> <code>net.ipv4.ip_forward = 1 (変更されていればOK)</code>
LVSの設定
keepalivedはデフォルトでipvsadmをラップしているので、LVSの設定はkeepalivedのコンフィグを編集して行います。
<code>[root@LB ~]# vim /etc/keepalived/keepalived.conf</code>
<code># LVSのeth0側のIP</code>
<code>virtual_server 10.5.0.133 80 {</code>
<code> # ヘルスチェック間隔</code>
<code> delay_loop 3</code>
<code> # 分散方式はround robinを使う</code>
<code> lb_algo rr</code>
<code> # パケット転送の方法はdirect routing (DSR)</code>
<code> lb_kind DR</code>
<code> protocol TCP</code>
<code> # Web 1</code>
<code> real_server 10.5.0.229 80 {</code>
<code> weight 1</code>
<code> # ヘルスチェック失敗時はweightをさげる</code>
<code> inhibit_on_failure</code>
<code> HTTP_GET {</code>
<code> url {</code>
<code> # ヘルスチェック用のページ</code>
<code> path /healthchk.html</code>
<code> status_code 200</code>
<code> }</code>
<code> connect_timeout 3</code>
<code> # ヘルスチェック失敗時の間隔</code>
<code> delay_before_retry 7</code>
<code> }</code>
<code> }</code>
<code> # Web 2</code>
<code> real_server 10.5.0.36 80 {</code>
<code> weight 1</code>
<code> #ヘルスチェック失敗時はweightをさげる</code>
<code> inhibit_on_failure</code>
<code> HTTP_GET {</code>
<code> url {</code>
<code> # ヘルスチェック用のページ</code>
<code> path /healthchk.html</code>
<code> status_code 200</code>
<code> }</code>
<code> connect_timeout 3</code>
<code> # ヘルスチェック失敗時の間隔</code>
<code> delay_before_retry 7</code>
<code> }</code>
<code> }</code>
<code>}</code>Step2. リアルサーバーの準備
Webサーバーのセットアップをします。
必要なパッケージをダウンロード
<code>[root@Web1 ~]# yum install -y httpd</code>
公開用のページとヘルスチェック用のページの作成
<code>[root@Web1 ~]# echo ‘Hi, this is Web1.’ > /var/www/html/index.html</code> <code># 後ほど公開するページを作成</code> <code># ここでは動作確認しやすいようにWeb1, Web2と区別する</code> <code>[root@Web1 ~]# echo ‘just a page for health check’ > /var/www/html/healthchk.html</code> <code># ヘルスチェック用のページを作成</code>
iptablesの記入
重要です。リアルサーバーがLVS宛のパケットを受け取ったとき、自分宛のパケットとして処理できるようにさせてあげる必要があります。
<code>[root@Web1 ~]# iptables -t nat -A PREROUTING -d 10.5.0.133 -j REDIRECT</code> <code># -d 10.5.0.133 の部分でご自身のLVSのIPを指定する</code> <code>[root@Web1 ~]# service iptables save</code>
Apacheの起動および自動起動設定
<code>[root@Web1 ~]# service httpd start</code> <code>[root@Web1 ~]# chkconfig httpd on</code>
Step3. keepalivedの起動
LVSもリアルサーバーも準備が出来たので、いよいよkeepalivedを起動して、様子を見てみます!
keepalivedの起動
<code>[root@LB ~]# service keepalived start</code>
動作確認
動作確認の一番手っ取り早い方法は、WebサーバーのApacheを落としてみて、切り替えができ ているか確認することになります。ブラウザ経由で確認できますし、LVS上でipvsadmコマンドでもバランシング対象のヘルスチェックが通っているかどうか確認できます。
<code>[root@LB ~]# ipvsadm -Ln</code> <code>IP Virtual Server version 1.2.1 (size=4096)</code> <code>Prot LocalAddress:Port Scheduler Flags</code> <code> -> RemoteAddress:Port Forward Weight ActiveConn InActConn</code> <code>TCP 10.5.0.133:80 rr persistent 10</code> <code> -> 10.5.0.36:80 Route 1 0 0 </code> <code> -> 10.5.0.229:80 Route 1 0 0 </code>
Web1とWeb2のIPが表示されました。重みが1なのでヘルスチェックが通っているという事ですね。続いて、Web1のApacheを落としてみます。
<code>[root@Web1 ~]# service httpd stop</code> <code>httpd を停止中: [ OK ]</code>
もう一度ipvsadmでみてみると、Web1はまだバランシング対象のリストに存在しますが、weightが0になっています。なので実際にトラフィックはWeb1に分散されません。
これはinhibit_on_failureをkeepalived.confで設定したからです。これによって障害時でもバランシングリストの確認が簡単にできるので、トラブルシューティングでも役立ちます。
<code>[root@LB ~]# ipvsadm -Ln</code> <code>IP Virtual Server version 1.2.1 (size=4096)</code> <code>Prot LocalAddress:Port Scheduler Flags</code> <code> -> RemoteAddress:Port Forward Weight ActiveConn InActConn</code> <code>TCP 10.5.0.133:80 rr persistent 10</code> <code> -> 10.5.0.36:80 Route 1 0 0 </code> <code> -> 10.5.0.229:80 Route 0 0 0 </code>
これで簡単な動作確認がとれました。ばっちりですね★
終わりに
みなさん、LVSの構築はいかがでしたか?とても簡単でわかりやすくてヘルスチェックもできるので、お手軽に使い始めて頂けます。
DSR方式を使用しているので、LVSがボトルネックになるのはほとんど無いと思います。そして仮想ルーターのロードバランサー機能を使わない事によって仮想ルーターのリソースにも余裕ができるので、大規模な構成を組む時はLVSがおすすめです!
今回はS1で構築してますが、もし処理性能を高めたい場合はCPUを増やすのが効果的です。IDCFクラウドのマシンタイプで言うとhighcpu.M4、highcpu.L8などが一番良い性能を出します。特にhighcpu.L8はコスパが一番良いかと思います!
ですが、もしLVSが落ちたらどうするの?という心配もきっとあるので、次回はkeepalivedでVRRPを使ってLVSを冗長化してみたいと思います。お楽しみに!
<関連記事>