こんにちは。プラットフォーム開発部の阿部です。
IDCFクラウド のYAMAHA vRXを使ってIDCFクラウドローカルとAWS間をVPN接続する方法を紹介します。
背景と目的
IDCFクラウドローカルのマシンとSSL-VPNを用いて、インターネット経由で外部クラウド環境等にアクセスを行うような構成が必要になる場合もあると思います。
そのような時、ネットワーク機器を別途購入して環境構築することもできると思いますが、IDCFクラウドで提供しているサービスを利用して構成することができるので、一例としてAWSとVPN接続の構築をこの回で実施したいと思います。
前提条件
・IDCFクラウドにて提供しているテンプレートイメージ「YAMAHA vRX(19.01.09)」を利用します。
・マシンのスペック(CPU、メモリ)を変更できますが、YAMAHAのシステム要件に沿ったものとします。
www.faq.idcf.jp
・IDCFクラウドのvRXライセンスは基本機能のみとなり、VPNなどのオプションはYAMAHAよりライセンスの別途調達が必要となります。
www.faq.idcf.jp
・本記事に記載のあるIPアドレスなどの固有情報はテスト用のため、実際に構築する環境の各サービスの制限に合わせて設定を行ってください。
構築の流れ
本記事ではVPN接続までを以下3段階に分けて記載します。
・1.ゲートウェイ構築
IDCFクラウドでのYAMAHA vRX構築方法について記載します。
・2.VRRP環境構築
前項で記載したYAMAHA vRXゲートウェイを2台で冗長化する方法について記載します。
・3.AWSとのVPN接続
IDCFクラウドでのYAMAHA vRXとAWSをVPN接続する方法について記載します。
構築手順
1.ゲートウェイ構築
〇構成図(vRXシングル構成)
![]()
〇IPアドレス
この項目では以下とします。
【vRX①】
LAN1:10.10.10.10
LAN2:10.20.20.10
パブリックIP:210.100.10.100
【サーバ①】
LAN1: 10.20.20.50
【サーバ②】
LAN1:10.10.10.51
LAN2:10.20.20.51
パブリックIP:210.100.10.110
1-1.IDCFクラウド 仮想マシン作成(vRX)
①.IDCFクラウドコンソールにログインして仮想マシン作成します。
「IDCFクラウドコンソール」→「コンピュート」→「仮想マシン」で「仮想マシン作成」をクリックします。
![]()
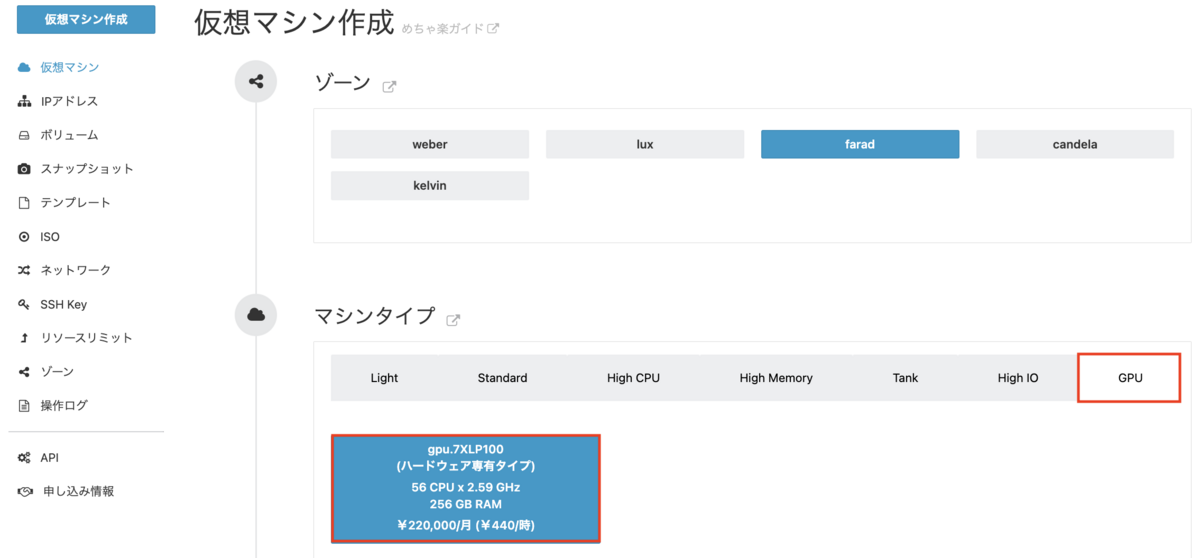
②.仮想マシンスペックの選択を実施
vRXの仮想マシンを作成します。
![]()
この記事では以下とします。
【vRX①】
* マシンタイプ:standard.M8
* イメージ:その他[YAMAHA vRX 19.01.09]
* ボリューム:ルートディスク10GB
* SSH Key:SSHキー選択(事前作成したユーザキーを指定)
* 詳細情報
ホスト名:vRXtest1
network1:10.10.10.10 DHCPで払い出すことも可能
network2:10.20.20.10 DHCPで払い出すことも可能
補足。
2つ目のnetworkについてはIDCFクラウドの[ネットワーク]から追加をお願いします。
www.idcf.jp
1-2.IDCFクラウド 仮想マシン作成(サーバ)
接続テスト用の仮想マシンを作成します。
この記事では以下とします。
【サーバ①】
* マシンタイプ:standard.S4
* イメージ:CentOS[Rokey Linux 9.2 64-bit]
* ボリューム:ルートディスク15GB
* SSH Key:SSHキー選択(事前作成したユーザキーを指定)
* 詳細情報
ホスト名:vrx-test-client
network2:10.20.20.50 DHCPで払い出すことも可能
【サーバ②】
* マシンタイプ:standard.S4
* イメージ:CentOS[Rokey Linux 9.2 64-bit]
* ボリューム:ルートディスク15GB
* SSH Key:SSHキー選択(事前作成したユーザキーを指定)
* 詳細情報
ホスト名:vrx-test-step
network1:10.10.10.51 DHCPで払い出すことも可能
network2:10.20.20.51 DHCPで払い出すことも可能
1-3.vRX基本設定
vRXに接続するための基本的な設定を実施します。
①.コンソール接続する
vRX初期設定のためvRXの仮想マシンにコンソール接続します。
「IDCFクラウドコンソール」→「コンピュート」→「仮想マシン」にて対象の仮想マシンのリンクをクリック、
対象の仮想マシンのウィンドウから「コンソール」→「コンソールにアクセスする」をクリックします。
![]()
②.vRXにログイン
ログインユーザが設定されていないため「Enter」打鍵で進みます。
![]()
③.管理ユーザに移行
初期の管理ユーザパスワードは空欄のためエンターで進みます。
> administrator
Password:
The administrator password is factory default setting. Please change the password by the 'administrator password' command.
#
④.任意のログインユーザ名とログインパスワード設定
# login user (ログインユーザー名) (任意のパスワード)
Password Strength : Strong
#
⑤.SSH サーバーホスト鍵を生成
# sshd host key generate
Generating public/private dsa key pair ...
|pass:[*******]
Generating public/private rsa key pair ...
|pass:[*******]
#
⑥.SSH サーバー機能を ON に設定
# sshd service on
#
⑦.IPアドレス設定
設定するIPアドレスはIDCFクラウドコンソールで指定したIPアドレスを指定します。
【vRX①】
# ip lan1 address 10.10.10.10/24
# ip lan2 address 10.20.20.10/24
# ip route default gateway 10.10.10.1
#
補足
ゲートウェイのIPアドレスは以下から対象のゲートウェイを確認できます。
「IDCFクラウドコンソール」→「コンピュート」→「ネットワーク」から対象のネットワーク名の[ゲートウェイ]の項目をご確認ください。
⑧.管理者パスワードを更新
# administrator password encrypted
Old_Password:
New_Password:
New_Password:
Password Strength : Strong
#
⑨.設定の保存
# save
#
1-4.パブリックIPアドレス作成
各マシンにネットワーク経由でSSHログインするためのパブリックIPアドレスを取得します。
この記事では以下とします。
vRX① :210.100.10.100
サーバ②:210.100.10.110
パブリックIPアドレスの作成方法およびNAT設定については以下をご参照ください。
www.idcf.jp
接続対象マシンへのアクセス制御設定については以下をご参照ください。
www.idcf.jp
1-5.SSH接続
この記事ではサーバ②を踏み台としてSSH接続する構成とています。
ローカル端末からサーバ②のパブリックIPアドレスに接続後、各マシンにSSH接続をしています。
IDCFクラウドの仮想マシンへのSSH接続方法については以下をご参照ください。
参考:IDCFクラウド めちゃ楽ガイド
1-6.vRXオプション設定
①.SSH認証鍵の登録
ログイン時の鍵認証に利用する鍵を作成します。
登録する秘密鍵は事前にローカル端末にて作成します。
# import sshd authorized-keys (ログインユーザ名)
(秘密鍵を登録)
#
②.時刻同期設定
時刻同期します。
# ntpdate ntp1.noah.idc.jp
#
IDCFクラウドにて利用化な時刻同期先は以下をご参照ください。
www.faq.idcf.jp
vRXの仕様上、定期的な時刻同期がされないため、スケジュール登録して時刻同期します。
# schedule at 1 */* 03:30 * ntpdate ntp1.noah.idc.jp
#
補足
vRX の時計は起動直後以外は自動的に同期を行わないため、長時間稼働させると徐々に正しい時刻からずれていきます。時間経過による時計のずれを補正する為にスケジュールで ntpdate コマンドを実行します。
③.DNS設定
DNSの登録を行います。ここではゲートウェイを指定します。
# dns server 10.42.0.1
#
④.NAT設定
NATの設定を行います。ローカルNWから外部に出るときのIPアドレスのNAT設定を追加します。
# nat descriptor type 1 masquerade
# nat descriptor address outer 1 10.10.10.10
# nat descriptor address inner 1 (ローカルの仮想マシンに配布するIPアドレス範囲を指定)
# ip lan1 nat descriptor 1
#
1-7.サーバのゲートウェイ設定
サーバ①においてvRX①LAN2のIPアドレスをデフォルトゲートウェイに指定します。
vRX①LAN2:10.20.20.10
ここまででサーバ①はvRXを中継して外部へのアクセスが可能になります。
2.VRRP構成
〇構成図(VRRP構成)
![]()
〇IPアドレス
この記事では以下とします。
【vRX①:master】
LAN1:10.10.10.101
LAN2:10.20.20.101
パブリックIP:210.100.10.100
LAN1 VRRP:10.10.10.10
LAN2 VRRP:10.20.20.10
【vRX②:backup】
LAN1:10.10.10.20
LAN2:10.20.20.20
【サーバ①】
LAN1:10.20.20.50
【サーバ②】
LAN1:10.10.10.51
LAN2:10.20.20.51
パブリックIP:210.100.10.110
2-1.IDCFクラウド 仮想マシン作成(vRX)
1-1の手順をご参照いただき仮想マシン作成を実施します。
この記事では以下とします。
【vRX②】
* マシンタイプ:standard.M8
* イメージ:その他[YAMAHA vRX 19.01.09]
* ボリューム:ルートディスク10GB
* SSH Key:SSHキー選択(事前作成したユーザキーを指定)
* 詳細情報
ホスト名:vRXtest2
network1:10.10.10.20 DHCPで払い出すことも可能
network2:10.20.20.20 DHCPで払い出すことも可能
2-2.vRX②設定
1-3,1-6の手順をご参照いただきvRX設定を実施します。
2-3.3つ目のIPアドレスの取得
VRRPを構成するために3つ目のIPアドレスを取得します。
IDCFクラウドコンソールより「ネットワーク」を選択後、3つ目のIPアドレスを払い出すネットワークの「ネットワーク名」のリンクを選択する。
![]()
ポップアップウィンドウにて「IPアドレス一覧」を選択すると、対象のネットワーク内で利用されているもしくはシステム上予約されているIPアドレスが表示されます。
![]()
IPアドレス一覧から種別が「仮想マシン用IP範囲外」となっているIPアドレス範囲を確認して、範囲内から利用可能なIPアドレスを一つ確認してください。
ここでは払い出す3つ目のIPアドレスを以下とします。
【ネットワーク/仮想マシン用IP範囲外】
NW1:10.10.10.101-10.10.10.254
→利用する3つ目のIPアドレス:10.10.10.101
NW2:10.20.20.101-10.20.20.254
→利用する3つ目のIPアドレス:10.20.20.101
補足
「仮想マシン用IP範囲外」のIPアドレスは仮想マシンに割りあてをされないIPアドレスとなります。
利用されているかどうかがシステム上管理をされないため、対象範囲から利用したIPアドレスは重複しないように管理をお願いします。
![]()
2-4.VRRP IPアドレス設定
vRX①のローカルIPアドレスをVRRPのアドレスに、空きとなったvRX①のローカルIPアドレスに前項で取得したIPアドレス設定します。
【vRX①】
# ip lan1 address 10.10.10.101/24
# ip lan1 vrrp 1 10.10.10.10 priority=200
# ip lan2 address 10.20.20.101/24
# ip lan2 vrrp 2 10.20.20.10 priority=200
#
【vRX②】
# ip lan1 vrrp 1 10.10.10.10 priority=100
# ip lan2 vrrp 2 10.20.20.10 priority=100
#
補足
vRX①のローカルIPアドレスをVRRPのアドレスに付け替える理由として
「仮想マシン用IP範囲外」のIPアドレスはIDCFクラウドコンソールでパブリックIPアドレスと紐づけができないため、「仮想マシン用IP範囲外」のIPアドレスをVRRPのIPアドレスとした場合、インターネットへのアクセスができません。
そのため、パブリックIPアドレスと紐づけ可能なvRX①のIPアドレスをVRRPのIPアドレスに利用します。
2-5.シャットダウントリガー設定
VRRPはプライオリティ設定でmaster側を優先にしているためインターフェースや片側のマシンに問題があった場合、backup側へ自動で切り替えを実施します。
【vRX①】
# ip lan1 vrrp shutdown trigger 1 lan2
# ip lan2 vrrp shutdown trigger 2 lan1
#
補足
今回の構成の場合、vRX①のLAN1もしくはLAN2の片方のみのインターフェースで問題が出た場合、LAN1のVRRPはvRX①、LAN2のVRRPはvRX②のような状況が発生し通信に影響が発生します。
そのため、vRX①側に片方のインタフェースが停止した場合、もう一方のインターフェースも停止させるトリガーを設定する方式としています。
2-6.NATするIPアドレスの変更設定
NATするouterのIPアドレスをVRRPのIPアドレスに変更します。
【vRX①】【vRX②】
# nat descriptor address outer 1 10.10.10.10
#
ここまででVRRP設定が完了となります。
3.AWSとのVPN接続
〇構成図(VPN接続構成)
![]()
〇IPアドレス
この記事では以下とします。
【vRX①:master】
LAN1:10.10.10.101
LAN2:10.20.20.101
パブリックIP:210.100.10.100
LAN1 VRRP:10.10.10.10
LAN2 VRRP:10.20.20.10
【vRX②:backup】
LAN1:10.10.10.20
LAN2:10.20.20.20
【サーバ①】
LAN1:10.20.20.50
【サーバ②】
LAN1:10.10.10.51
LAN2:10.20.20.51
パブリックIP:210.100.10.110
〇本項目の前提
・AWS側のVPCやsubnetはすでに作成されている前提で解説します。
・AWSのSite to site VPN(インターネット網での環境A←→環境Bの接続)を利用してVPN接続します。
・AWSのVPNトンネルは2つが自動作成されます。
・BGPでの動的ルーティングではなく静的ルーティングで設定を行います。
・AWSのUIについては本掲載作成時点の内容で作成しており、変更される場合があります。
3-1.AWS カスタマーゲートウェイ(CGW)の作成
ーーーー本項はAWS側の操作となります。ーーー
AWSの画面にて[VPC]>[カスタマーゲートウェイ]>[カスタマーゲートウェイの作成]を選択します。
![]()
[カスタマーゲートウェイの作成]の画面で、下記の項目を入力し、[カスタマーゲートウェイの作成]ボタンをクリックします。
![]()
[名前]:任意ですが、「vRX-test-cgw」とします。
[BGP ASN]:静的ルート利用のためデフォルト「65000」のままとします。
BGPを利用する場合は、ASNの優先を検討して変更をお願いします。
[IPアドレス]:vRXのパブリックIPアドレス[210.100.10.100]を入力します。
3-2.AWS 仮想プライベートゲートウェイ(VPGW)の作成
AWSの画面にて[VPC]>[仮想プライベートゲートウェイ]>[仮想プライベートゲートウェイの作成]をクリックします。
![]()
[仮想プライベートゲートウェイの作成]の画面で、下記の項目を入力し、[仮想プライベートゲートウェイの作成]ボタンをクリックします。
![]()
[名前タグ]:任意ですが「vRX-test-vgw」とします。
[カスタムASN]:ここではデフォルトのままとします。
3-3.AWS 作成した仮想プライベートゲートウェイ(VPGW)をVPCに適用
[仮想プライベートゲートウェイの作成]の画面で前項で作成した「仮想プライベートゲートウェイ」を選択後、[アクション]>[VPCにアタッチ]をクリックします。
![]()
[VPCへアタッチ]の画面で適用対象のVPCを選択後、[VPCへアタッチ]ボタンをクリックします。
![]()
3-4.AWS ルートテーブルの追加
VPCからIDCFクラウドのローカル環境への静的ルートの追加をします。
AWSの画面にて[VPC]>[ルートテーブル]をクリック、対象のルートテーブルを選択後、[アクション]>[ルートを編集]をクリックします。
![]()
[ルートを編集]の画面で以下のルートを追加後[設定を保存]ボタンをクリックします。
![]()
ルート①
[送信先]:10.10.10.0/24
[ターゲット]:仮想プライベートゲートウェイ:vRX-test-vgw
ルート②
[送信先]:10.20.20.0/24
[ターゲット]:仮想プライベートゲートウェイ:vRX-test-vgw
3-5.AWS Site-to-Site VPN 接続の作成
カスタマーゲートウェイと仮想プライベートゲートウェイを紐づけします。
AWSの画面にて[VPC]>[Site-to-Site VPN 接続]>[VPN接続を作成する]をクリックします。
![]()
[VPN接続を作成する]の画面で以下を設定します。
![]()
[名前タグ]:任意ですが「vRX-test-VPN」とします。
ゲートウェイの選択
![]()
[ターゲットゲートウェイのタイプ]:「仮想プライベートゲートウェイ」を選択します。
[仮想プライベートゲートウェイ]:事前作成した「vRX-test-vgw」を選択します。
[カスターマーゲートウェイ]:「既存」を選択します。
[カスタマーゲートウェイID]:事前作成した「vRX-test-cgw」を選択します。
ルーティングオプションの選択
![]()
[ルーティングオプション]:「静的」を選択します。
[静的IPプレフィックス]:「10.10.10.0/24」「10.20.20.0/24」を追加します。
ネットワークCIDRの設定
ここではデフォルトのままとします。
![]()
設定が問題なければ[VPN接続を作成する]ボタンをクリックします。
![]()
3-6.AWS 設定のダウンロード
vRXに適用するトンネル設定のダウンロードを行います。
AWSの画面にて[VPC]>[Site-to-Site VPN 接続]をクリック、対象のVPN接続を選択後、[設定をダウンロードする]をクリックします。
![]()
[設定をダウンロードする]の画面で以下を選択して[ダウンロード]ボタンをクリックします。
![]()
[ベンダー]:「Yamaha」を選択します。
[プラットフォーム]:「RTX Routers」を選択します。
[ソフトウェア]:「Rev10.01.16+」を選択します。
[IKEバージョン]:「ikev2」を選択します。
ローカル端末にvRXに適用するトンネル情報が記載されたコンフィグファイルがダウンロードされます。
3-7.vRX トンネル設定の適用
ーーーーここはvRX側での操作となります。ーーー
3-6でダウンロードしたファイルを参照して必要に応じて適用します。
以下サンプルコンフィグとなります。環境に合わせて変更してください。
【vRX①】
administrator password *
login user (ログインユーザ) *
vrx user (ライセンスユーザ) *
ip route default gateway 10.10.10.1
ip route 10.0.0.0/20 gateway tunnel 1 keepalive 1 gateway tunnel 2 weight 0
ip keepalive 1 icmp-echo 10 3 (Tunnel1側のAWS側ルータの外部IPアドレス)
ip lan1 address 10.10.10.101/24
ip lan1 nat descriptor 1
ip lan1 vrrp 1 10.10.10.10 priority=200
ip lan1 vrrp shutdown trigger 1 lan2
ip lan2 address 10.20.20.101/24
ip lan2 vrrp 2 10.20.20.10 priority=200
ip lan2 vrrp shutdown trigger 2 lan1
tunnel select 1
ipsec tunnel 201
ipsec sa policy 201 1 esp aes-cbc sha-hmac
ipsec ike version 1 2
ipsec ike duration ipsec-sa 1 3600
ipsec ike duration isakmp-sa 1 28800
ipsec ike encryption 1 aes-cbc
ipsec ike group 1 modp1024
ipsec ike hash 1 sha
ipsec ike keepalive use 1 on rfc4306 10 3
ipsec ike local address 1 10.10.10.10
ipsec ike local name 1 10.10.10.10 ipv4-addr
ipsec ike pfs 1 on
ipsec ike message-id-control 1 on
ipsec ike child-exchange type 1 2
ipsec ike pre-shared-key 1 *
ipsec ike remote address 1 (AWS側ルータの外部IPアドレス)
ipsec ike remote name 1 (AWS側ルータの外部IPアドレス) ipv4-addr
ipsec ike negotiation receive 1 off
ipsec tunnel outer df-bit clear
ip tunnel address (AWS側ルータの内部IPアドレス)
ip tunnel remote address (AWS側ルータの内部IPアドレス)
ip tunnel tcp mss limit auto
tunnel enable 1
tunnel select 2
ipsec tunnel 202
ipsec sa policy 202 2 esp aes-cbc sha-hmac
ipsec ike version 2 2
ipsec ike duration ipsec-sa 2 3600
ipsec ike duration isakmp-sa 2 28800
ipsec ike encryption 2 aes-cbc
ipsec ike group 2 modp1024
ipsec ike hash 2 sha
ipsec ike keepalive use 2 on rfc4306 10 3
ipsec ike local address 2 10.10.10.10
ipsec ike local name 2 10.10.10.10 ipv4-addr
ipsec ike pfs 2 on
ipsec ike message-id-control 2 on
ipsec ike child-exchange type 2 2
ipsec ike pre-shared-key 2 *
ipsec ike remote address 2 (AWS側ルータの外部IPアドレス)
ipsec ike remote name 2 (AWS側ルータの外部IPアドレス) ipv4-addr
ipsec ike negotiation receive 2 off
ipsec tunnel outer df-bit clear
ip tunnel address (AWS側ルータの内部IPアドレス)
ip tunnel remote address (AWS側ルータの内部IPアドレス)
ip tunnel tcp mss limit auto
tunnel enable 2
nat descriptor type 1 masquerade
nat descriptor address outer 1 10.10.10.10
nat descriptor address inner 1 10.20.20.2-10.20.20.100
nat descriptor masquerade static 1 1 10.10.10.10 esp
nat descriptor masquerade static 1 2 10.10.10.10 udp 500
nat descriptor masquerade static 1 3 10.10.10.10 udp 4500
ipsec use on
ipsec auto refresh on
telnetd service off
dns server 10.10.10.1
schedule at 1 */* 03:30 * ntpdate ntp1.noah.idc.jp
sshd service on
sshd host key generate *
【vRX②】
administrator password *
login user (ログインユーザ) *
vrx user (ライセンスユーザ) *
ip route default gateway 10.42.0.1
ip route 10.0.0.0/20 gateway tunnel 1 keepalive 1 gateway tunnel 2 weight 0
ip keepalive 1 icmp-echo 10 3 (Tunnel1側のAWS側ルータの外部IPアドレス)
ip lan1 address 10.10.10.20/24
ip lan1 nat descriptor 1
ip lan1 vrrp 1 10.10.10.10 priority=100
ip lan2 address 10.20.20.20/24
ip lan2 vrrp 2 10.20.20.10 priority=100
tunnel select 1
ipsec tunnel 201
ipsec sa policy 201 1 esp aes-cbc sha-hmac
ipsec ike version 1 2
ipsec ike duration ipsec-sa 1 3600
ipsec ike duration isakmp-sa 1 28800
ipsec ike encryption 1 aes-cbc
ipsec ike group 1 modp1024
ipsec ike hash 1 sha
ipsec ike keepalive use 1 on rfc4306 10 3
ipsec ike local address 1 10.10.10.10
ipsec ike local name 1 10.10.10.10 ipv4-addr
ipsec ike pfs 1 on
ipsec ike message-id-control 1 on
ipsec ike child-exchange type 1 2
ipsec ike pre-shared-key 1 *
ipsec ike remote address 1 (AWS側ルータの外部IPアドレス)
ipsec ike remote name 1 (AWS側ルータの外部IPアドレス) ipv4-addr
ipsec ike negotiation receive 1 off
ipsec tunnel outer df-bit clear
ip tunnel address (AWS側ルータの内部IPアドレス)
ip tunnel remote address (AWS側ルータの内部IPアドレス)
ip tunnel tcp mss limit auto
tunnel enable 1
tunnel select 2
ipsec tunnel 202
ipsec sa policy 202 2 esp aes-cbc sha-hmac
ipsec ike version 2 2
ipsec ike duration ipsec-sa 2 3600
ipsec ike duration isakmp-sa 2 28800
ipsec ike encryption 2 aes-cbc
ipsec ike group 2 modp1024
ipsec ike hash 2 sha
ipsec ike keepalive use 2 on rfc4306 10 3
ipsec ike local address 2 10.10.10.10
ipsec ike local name 2 10.10.10.10 ipv4-addr
ipsec ike pfs 2 on
ipsec ike message-id-control 2 on
ipsec ike child-exchange type 2 2
ipsec ike pre-shared-key 2 *
ipsec ike remote address 2 (AWS側ルータの外部IPアドレス)
ipsec ike remote name 2 (AWS側ルータの外部IPアドレス) ipv4-addr
ipsec ike negotiation receive 2 off
ipsec tunnel outer df-bit clear
ip tunnel address (AWS側ルータの内部IPアドレス)
ip tunnel remote address (AWS側ルータの内部IPアドレス)
ip tunnel tcp mss limit auto
tunnel enable 2
nat descriptor type 1 masquerade
nat descriptor address outer 1 10.10.10.10
nat descriptor address inner 1 10.20.20.2-10.20.20.100
nat descriptor masquerade static 1 1 10.10.10.10 esp
nat descriptor masquerade static 1 2 10.10.10.10 udp 500
nat descriptor masquerade static 1 3 10.10.10.10 udp 4500
ipsec use on
ipsec auto refresh on
telnetd service off
dns server 10.10.10.1
schedule at 1 */* 03:30 * ntpdate ntp1.noah.idc.jp
sshd service on
sshd host key generate *
sftpd host any
3-8.IDCFクラウドのFW許可設定
ーーーーここはIDCFクラウドコンソールでの操作となります。ーーー
IDCFクラウドコンソールにて「vRX①」に割り当てているパブリックIPアドレスのファイアウォール設定でVPN接続に必要なポートの許可設定を実施します。
ファイアウォール設定方法は以下をご参照ください。
www.idcf.jp
許可設定対象は以下です。
[対象ポート]
TCP/UDP 50
UDP 500
UDP 4500
[ソースCIDR]
(AWS側ルータの外部IPアドレス)2つを指定します。
ここまででIDCFクラウドのマシンとAWSのインスタンス間の疎通が取れるようになります。
まとめ
以上のように、IDCFクラウドで提供されている機能や資源を利用して、VPN環境を用意することがができます。
ぜひ、本記事をご参考にしてVPN環境の構築をお試していたければと存じます。
▼参考にさせていただいた資料▼
YAMAHA作成のvRX導入するためのユーザガイド
www.rtpro.yamaha.co.jp
YAMAHA作成のvRXのコマンドリファレンス
www.rtpro.yamaha.co.jp
ーーー
Amazon Web Services、AWSは、Amazon.com, Inc. またはその関連会社の商標です。